KV Cache终于不用无脑全留了!百度&复旦用「投资回报率」重新分配缓存|ICML 2026
KV Cache终于不用无脑全留了!百度&复旦用「投资回报率」重新分配缓存|ICML 2026随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。
来自主题: AI技术研报
9863 点击 2026-06-15 09:18
 搜索
搜索
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。

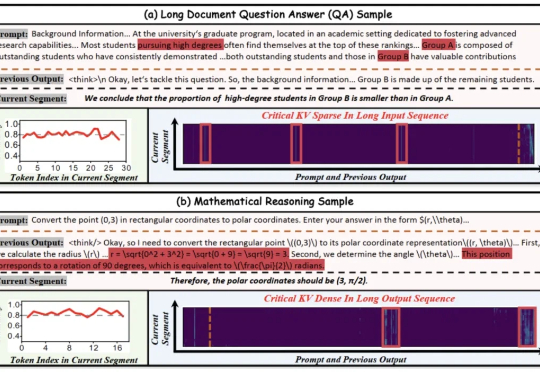
长上下文模型越来越能“记”,但真正让它们跑到线上时,最先顶不住的往往不是算力,而是KV Cache。
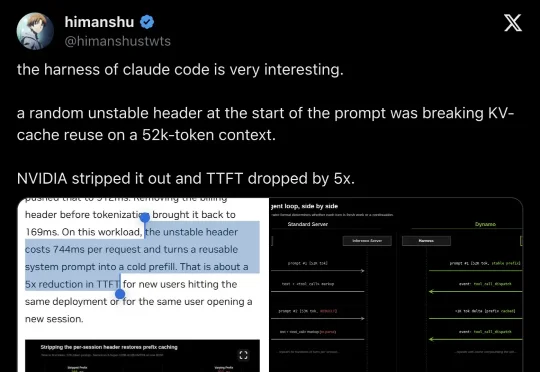
NVIDIA Dynamo 团队发现,Claude Code 向自定义端点发送请求时,prompt 最前面会带一行 session-specific billing header。这行 header 每个 session 都变,导致 52K token 的稳定前缀在 KV cache 中无法复用——TTFT 从 168ms 飙到 912ms。Dynamo 加了一个 `
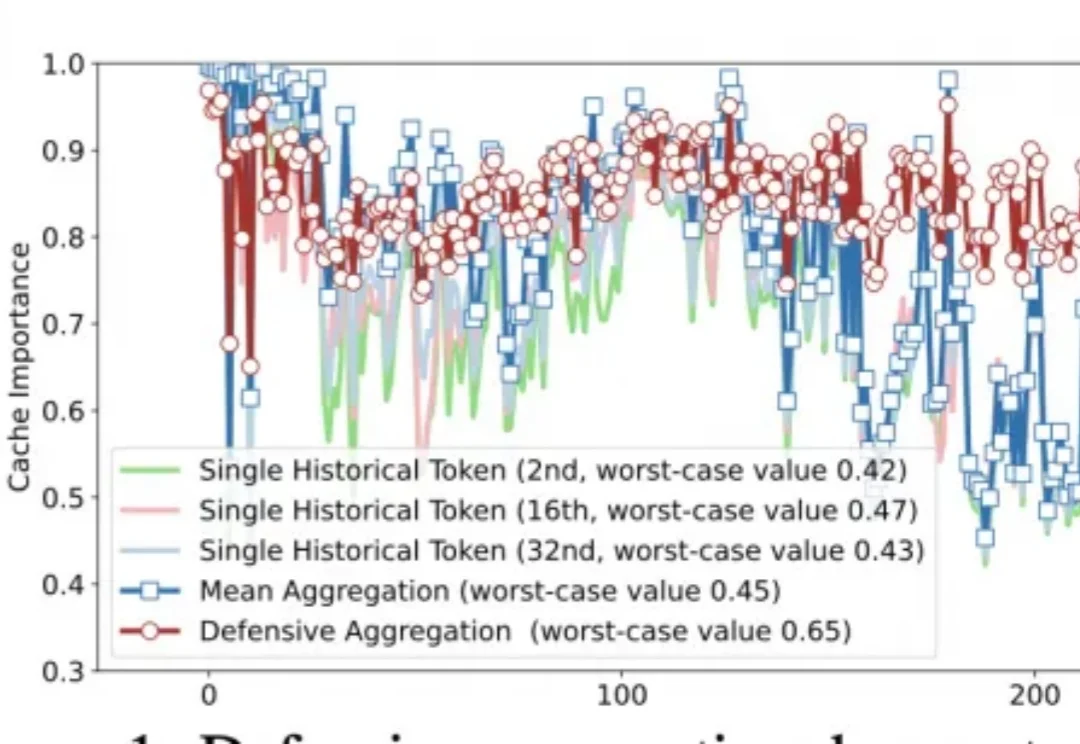
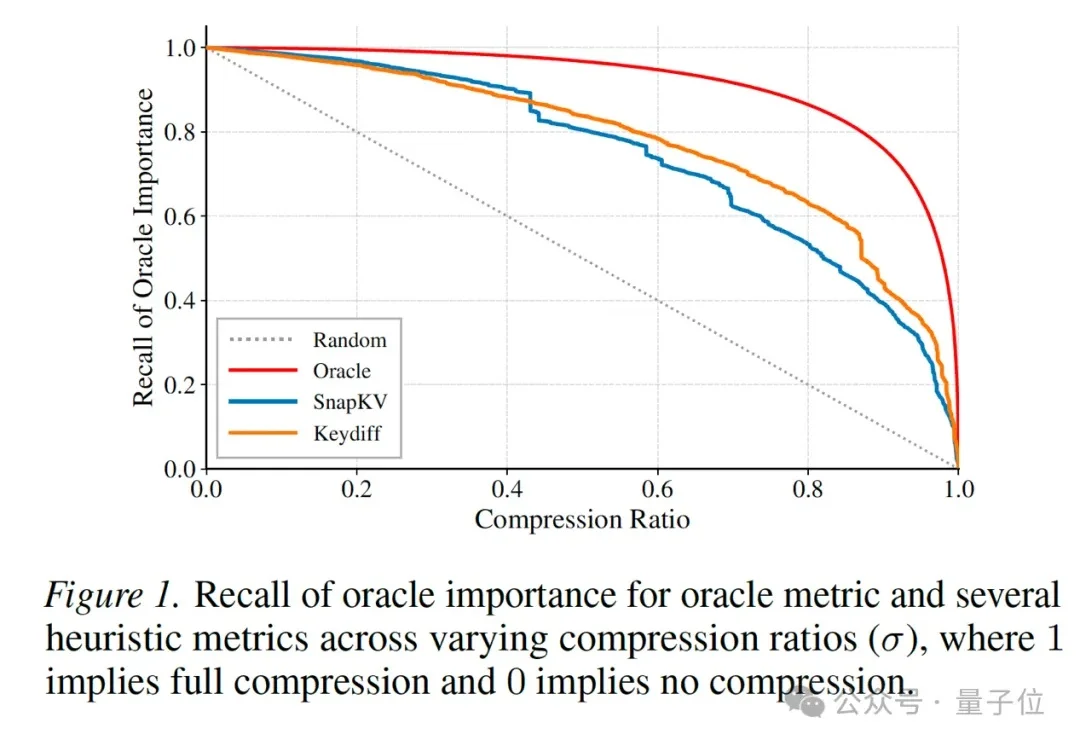
随着大模型长上下文能力快速增长,海量 KV Cache 存储需求急剧增加,各类 KV Cache 压缩方法如雨后春笋般涌现。然而,这些方案在真实场景中的工程落地却常常陷入困境。
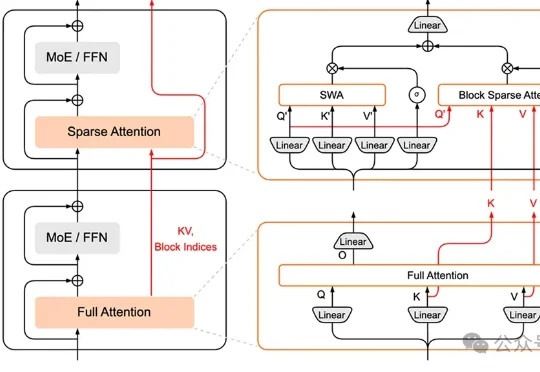
小米MiMo大模型团队,加入AI拜年战场——推出HySparse,一种面向Agent时代的混合稀疏注意力架构。
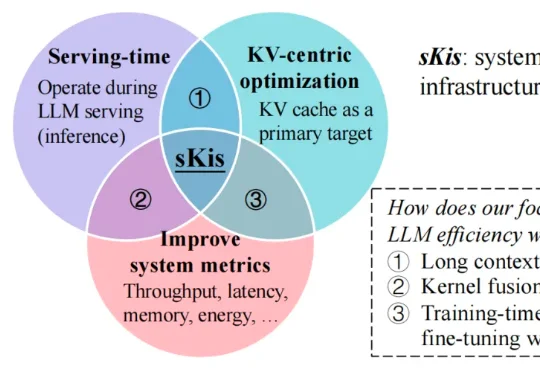
近期,来自墨尔本大学和华中科技大学的研究者们发布了一篇深度综述,从 MLSys 的思维出发,用一套新颖的「时间 - 空间 - 结构」系统行为视角对 KV cache 优化方法进行了系统性梳理与深入分析,并将相关资源整理成了持续维护的 Awesome 资源库,方便研究者与从业人员快速定位与落地。
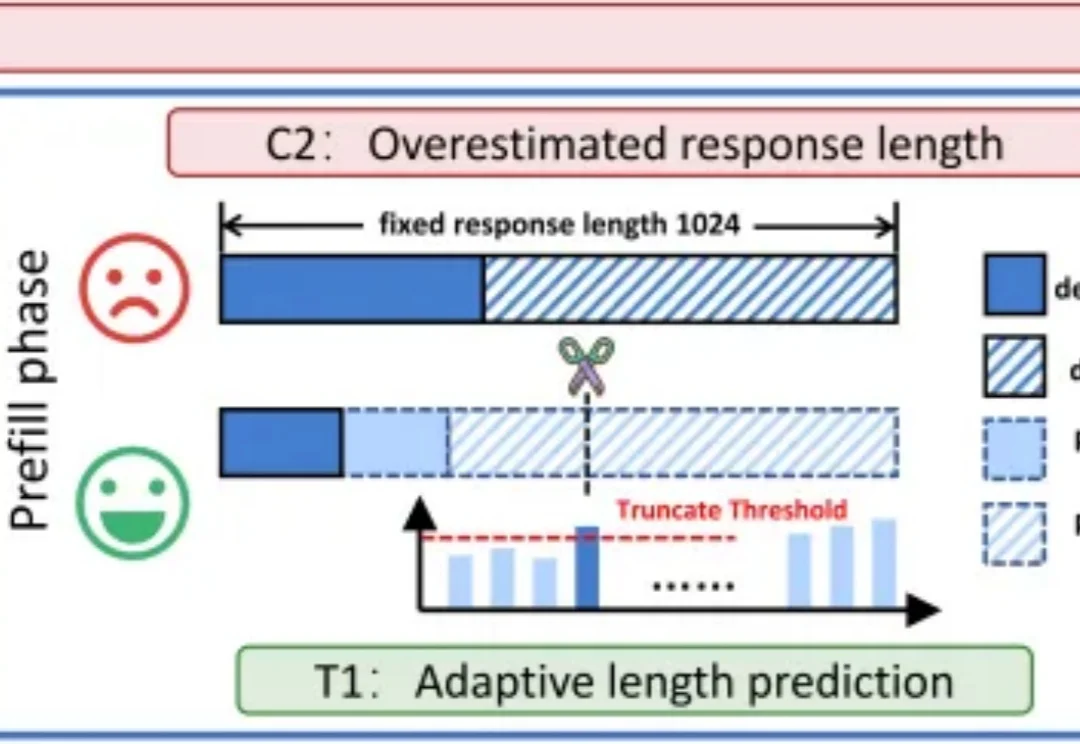
基于扩散的大语言模型 (dLLM) 凭借全局解码和双向注意力机制解锁了原生的并行解码和受控生成的潜力,最近吸引了广泛的关注。例如 Fast-dLLM 的现有推理框架通过分块半自回归解码进一步实现了 dLLM 对 KV cache 的支持,挑战了传统自回归 LLMs 的统治地位。
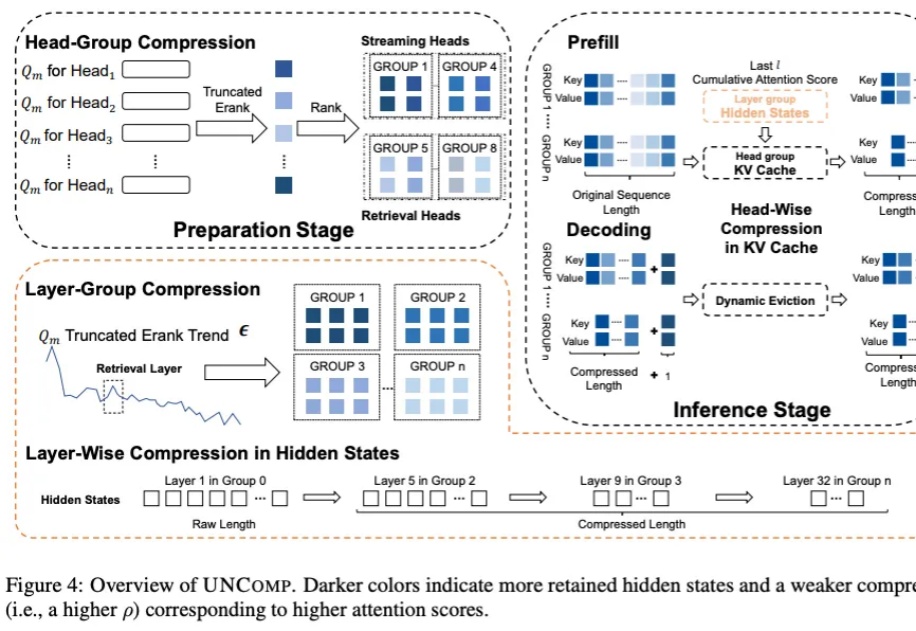
我们都知道 LLM 中存在结构化稀疏性,但其底层机制一直缺乏统一的理论解释。为什么模型越深,稀疏性越明显?为什么会出现所谓的「检索头」和「检索层」?
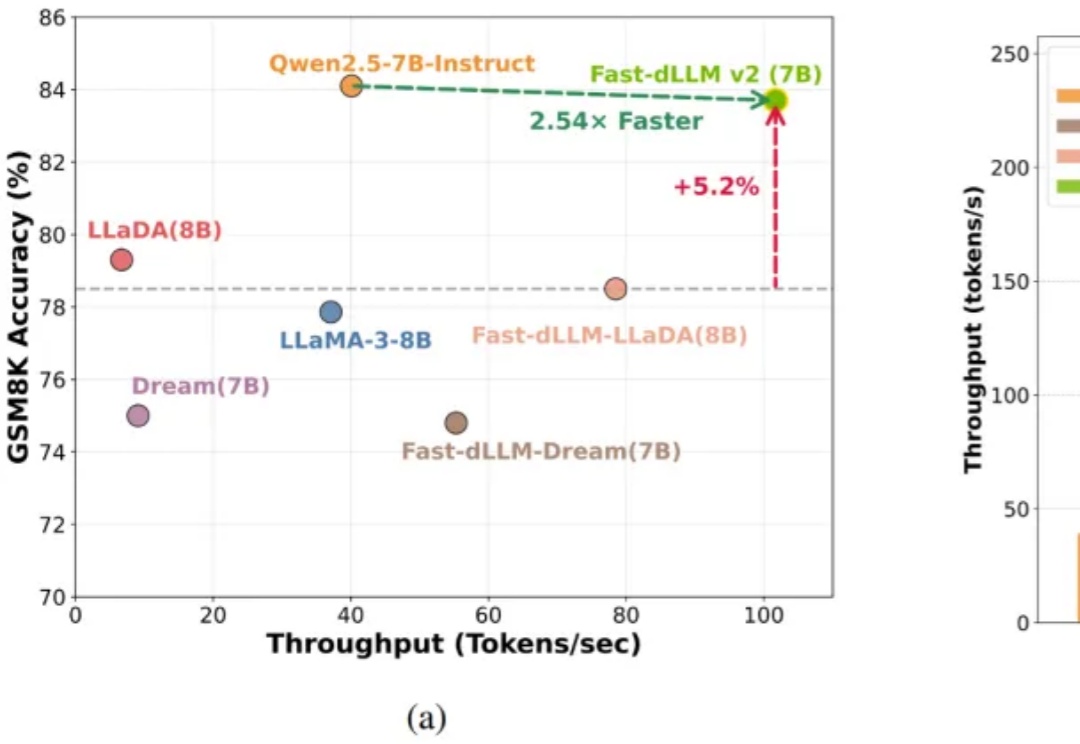
自回归(AR)大语言模型逐 token 顺序解码的范式限制了推理效率;扩散 LLM(dLLM)以并行生成见长,但过去难以稳定跑赢自回归(AR)模型,尤其是在 KV Cache 复用、和 可变长度 支持上仍存挑战。
北大华为联手推出KV cache管理新方式,推理速度比前SOTA提升4.7倍! 大模型处理长序列时,KV cache的内存占用随序列长度线性增长,已成为制约模型部署的严峻瓶颈。